Land cover datasets
In my day job, I work on the ecology of Mediterranean ecosystems in southern France, and if you work on a particular type of ecosystem, the first thing you need to know is where you can find your ecosystem! Seems like a simple problem, but it’s not.
How might we start? Go out and take a look? That’s fine, as far as it goes, but it’s labour-intensive and it can be tricky to compare manual observations from different time periods for changes in land cover. We’ll come back to that in a minute. What about aerial photos? They’re available for many regions of the globe, and they’ve been around a lot longer than satellite data. Here’s an aerial photo of a small region (about 8.5 km by 7 km) near an experimental station we have at Puéchabon in the Languedoc-Roussillon region of southern France, about 30 km from Montpellier.

We can see a river, roads, some fields (easy to spot both because of their colour and their geometry), some areas that look less vegetated (the grey parts north of the fields), some parts that look more vegetated (mostly around the greyer parts). But can we tell which areas are predominantly covered by Quercus ilex (holm oak) woodlands? That’s a bit tougher. Detailed examination of high resolution images can be enough to identify vegetation assemblages, but there’s often just not enough information in a simple visible light photograph (in the usual digital rendering, just three spectral channels for red, green and blue) to pick out more subtle differences. And before the 1970s, most aerial photographs were black and white, which makes things even harder.
For some regions of the world, there are in fact pretty good inventories of the “go out and take a look” kind. For France, the Inventaire Forestier National (IFN) collects vegetation inventory information for forestry applications. Here’s a plot of their data for the same region as shown in the aerial photo:
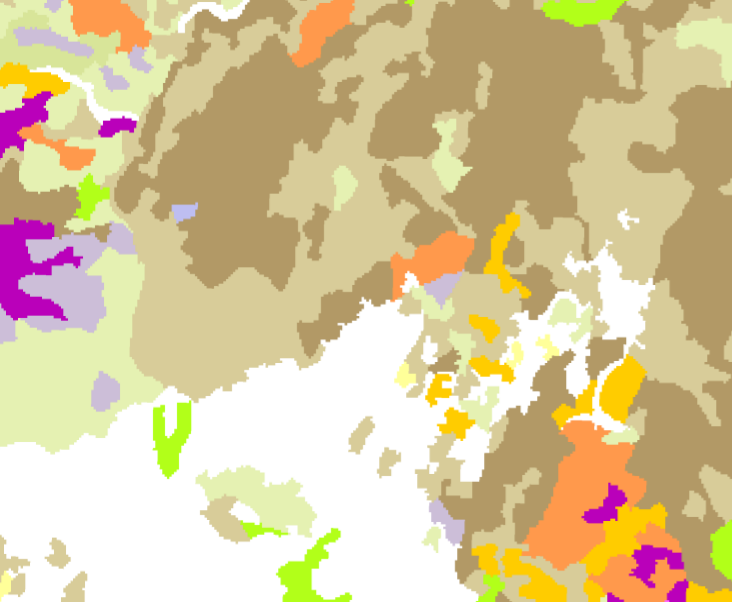 IFN inventory data
IFN inventory data  IFN legend
IFN legend There’s a pretty good correspondence between the units from the IFN data and the units that are visible on the aerial photograph, which lends some confidence to the classification that we see. There are three problems though. First, this data has been developed for forestry use. There are large white “unclassified” areas where there is no data, because there are no economically interesting trees there. For some ecological applications, that’s not much of a hindrance, but it can be a problem for others. Second, to understand what you’re seeing in a data set like this, you need to know quite a bit about the survey method used for the inventory and the statistical methods used to interpolate to a map view. For the IFN data, this is well documented, which makes the data relatively easy to use, but that level of documentation is more the exception than the rule. And finally, this data is difficult to collect: a ground-based survey of the entire country requires a lot of resources and so it can’t be done all that often. (For some reason, Spain does very well in this regard. They have really good forestry data collected on a regular basis across the whole of the country. Good for them!)
What about some combination of aerial photography and ground-based observations to serve as some sort of reference? This is a good approach in many cases: it allows for a more reasonable use of resources for surveying, and it can produce new data sets as new aerial photography comes in. I use two different data sets of this type, both produced in broadly similar ways, called CORINE (which covers the whole of Europe) and OCSOL (which covers only the Languedoc-Roussillon and PACA regions of southern France). Both of these data sets use ground-based observations with contemporaneous aerial photography to construct sets of rules for classifying land cover types from photographs. The rules tend to be quite complicated, relying on both basic spectral data (trees are green, water is blue, rock is grey, that sort of thing), geometric classification (fields tend to have square boundaries, rivers are roads are mostly linear features, and so on) and a combination of the two, possibly with other factors (greenhouses are squarish shiney things that often appear in regular groups). Along with some ancillary rules to control the geometry of the resulting data set (no near singular triangles, for example), this provides a system for going from aerial photographs of a region to a data set of polygons classified by land cover type. So how well does it work? Both CORINE and OSCOL use more or less the same classification scheme, with the following classes:

and here is what the data looks like for the same region as shown in the aerial photo and the IFN data above:
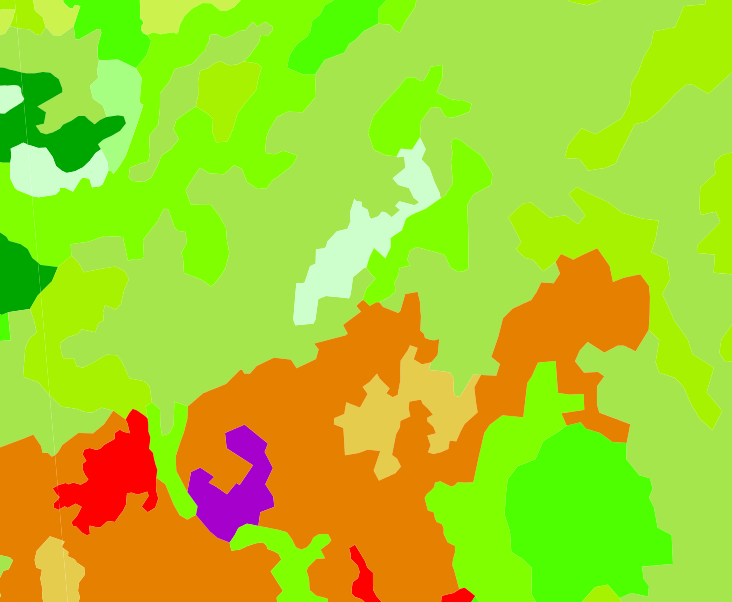 CORINE land cover
CORINE land cover 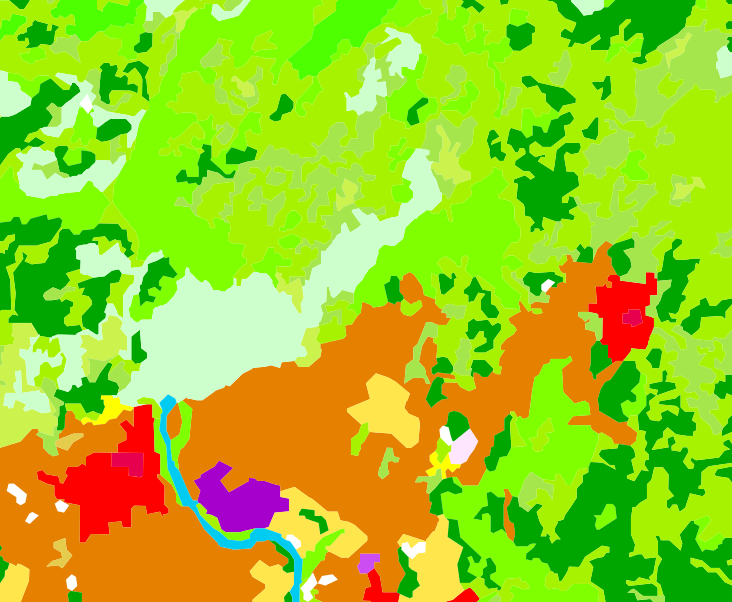 OCSOL land cover
OCSOL land cover Hmmm… Not so awesome. Land cover units in the data sets don’t bear a strong resemblance to the land cover units you can see in the aerial photograph, and they don’t correspond all that closely to the vegetation units in the IFN data (which is probably closer to the “truth”, since it’s survey-based everywhere, while the CORINE and OCSOL data uses rules calibrated in some parts of the region of application to determine land cover type in other parts of the region).
For a further comparison, we can think about what sort of remote sensing products we might try to use to determine the land cover type. With remote sensing data, we have a good chance of getting a regular time series of data (annual land cover maps from MODIS, for instance), which is harder to get via any other method. The downside? Spatial resolution is pretty terrible, and classification accuracy is patchy. Here’s the MODIS data for 2006 (same year as the CORINE data and the aerial photo) for the region we’re looking at:
 MODIS land cover
MODIS land cover  MODIS legend
MODIS legend The spatial resolution here is about 500 m, compared to about 25 m for the IFN data and whatever you want to believe for the CORINE and OCSOL vector data sets (their resolution is defined in terms of the minimum area of land cover feature that they include, rather than a regular grid-based resolution limit). It’s actually very unfair to compare MODIS data to data produced by land-based surveys, but we don’t really care too much about fair in this game: we just want good data.
Let’s look at a comparison between some of these data sets in a slightly more quantitative way. Eyeball is fine, but just how bad is the correspondence between these different data sets? Let’s compare CORINE with MODIS first. Gaze at this technicolour horror for a few seconds:
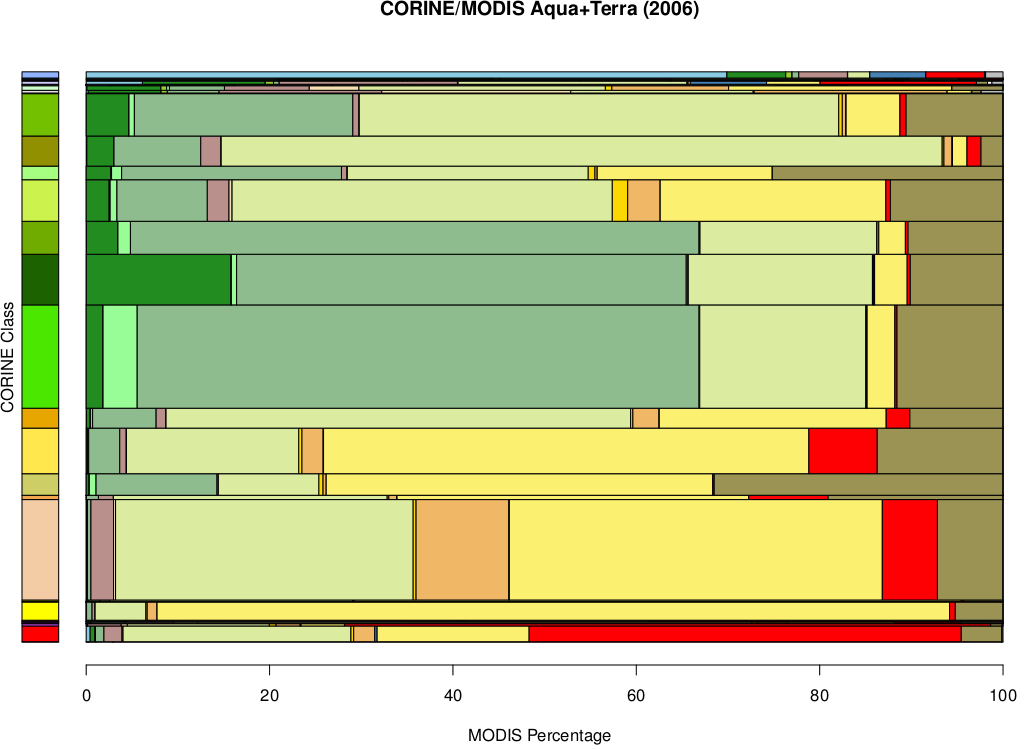
What this is showing is, in the vertical bar on the left, the overall classification across the whole of the Languedoc-Roussillon region, according to CORINE, and in the main part of the plot, how the portion of the land surface in each of those CORINE classes was classified according to the MODIS data. If we take a look at the two most common CORINE classes, broad-leaved and coniferous forest, we see that these are mostly, but not exclusively, classified as forest in the MODIS data, but there’s quite a lot of mixing of classifications between the different forest types. The same kind of phenomena is seen in the other classes: areas classified as urban by CORINE are about 50% classified as urban in the MODIS data and about 50% something else. One possible complaint about this comparison is of a resolution mismatch between CORINE and MODIS: the CORINE data is a vector data set with pretty high spatial resolution, while the MODIS data is on a 500 m grid (more or less). We can do a similar comparison between CORINE and OCSOL though, both of which are vector data sets, though OCSOL has a smaller minimum area for land cover units it will consider. Here’s the same sort of comparison plot as for the CORINE/MODIS comparison:
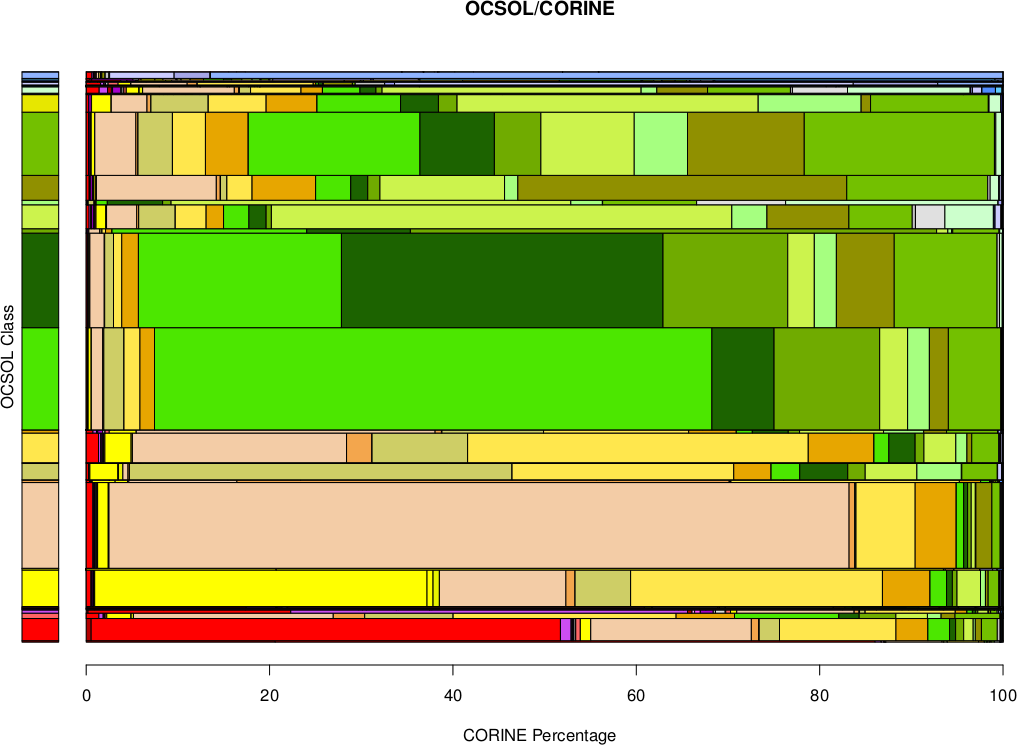
The comparison is a little easier here, since CORINE and OCSOL use more or less the same classification so we can use the same colour scales. That means that blocks in the main part of the plot that are the same colour as the bars in the left hand part of the plot are classified consistently between the two data sets. Even though these methods ostensibly use similar methods to classify land cover, the correspondence between the two data sets is not great. For instance, of the area that is classified as coniferous forest by OCSOL, only about 40% is also classified as coniferous forest by CORINE.
So, what do we do? It’s difficult to come up with any concrete recommendations that aren’t very tightly tied to specific applications, since everyone’s detailed needs are different. For my work, I’m most interested in assemblages including Quercus ilex, Quercus pubescens, Pinus halepensis and shrub species that can be bundled up into a generic “garrigue” classification. For the individual tree species, the IFN data is very good. For identifying garrigue sites, it’s a bit less good, so I use OCSOL for that. The same goes for grasslands, when I need them.
It’s a bit daunting that what would appear to be the simplest possible remote sensing/geostatistical data question, that is “What’s there on the ground?” turns out to be so difficult to answer. The geography and history of this part of France does make the disposition of land cover particularly complex, but something like this problem is going to be encountered more or less anywhere in the world.