AI Class: Machine Learning
Week 3 of the Stanford AI class was about machine learning. This was kind of handy for me, since my PhD thesis was mostly about applying some unsupervised learning techniques to dimensionality reduction for climate model output. That mean that I’ve read hundreds of papers about this stuff so the basic ideas and even quite a few of the details are already pretty familiar. However, most of what I’ve read has been aimed at applications in climate science and dynamical systems theory. Not much from the huge literature on clustering methods, for instance.
Sebastian very briefly mentioned some of the nonlinear dimensionality reduction methods that have been developed for unsupervised learning applications, but it was nothing more than a mention (no time for anything else). I can’t resist the temptation to dust off a little of this stuff from the archives.
Sebastian mentioned two methods of nonlinear dimensionality reduction (the two most well known), locally linear embedding S. T. Roweis & L. K. Saul (2000). Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500), 2323-2326. Link and Isomap J. B. Tenenbaum et al. (2000). A global geometric framework for nonlinear dimensionality reduction. Science 290(5500), 2319-2323. Link (Isomap is one of the methods I used in my thesis I. Ross et al. (2008). ENSO dynamics in current climate models: an investigation using nonlinear dimensionality reduction. Nonlin. Processes Geophys. 15(2), 339-363. Link ). There are dozens of other methods that have been developed, and I’d like to describe the characteristics of one of the more recent ones, called Hessian locally linear embedding (HLLE). As the name suggests, it has a lot in common with locally linear embedding, but it turns out to be easier to deal with from a theoretical point of view, and has some rather nice properties.
The basic idea of HLLE
HLLE D. L. Donoho & C. Grimes (2003). Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proc. Natl. Acad. Sci. USA 100(10), 5591-5596. Link is a manifold learning method. That means that, given a set of data points lying in m-dimensional Euclidean space, it tries to find (an approximation to) a p-dimensional manifold close to which the data points lie. Such methods can be thought of as generalisations of principal components analysis (PCA), where PCA finds linear subspaces, instead of curved manifolds. The Isomap method does this by trying to build a distance measure between the data points that approximates distances along paths in the data manifold. This distance measure can then be used to “unroll” the manifold using multidimensional scaling. Locally linear embedding works by using a numerical approximation of the Laplace-Beltrami operator on the data manifold (a generalisation of the usual Laplacian operator to manifolds). An eigenvalue decomposition of this numerical Laplace-Beltrami operator is then used to generate “coordinates” for the manifold Furious hand waving going on here. There’s a better, but much more mathematical, explanation in Chapter 8 of my thesis… . HLLE works in a similar way, but uses a numerical approximation to the Hessian matrix on the manifold (actually a sort of coordinate-invariant operator built from the Hessian), which is a generalisation of the matrix of second partial derivatives in Euclidean spaces.
The key observation here is that the null space of this Hessian operator is closely related to the existence of nice “flat” coordinates for the data manifold, in a much better way than the null space of the Laplacian. (Lots of functions have zero Laplacian without being “simple”. Functions with zero Hessian have all second derivatives zero, so are just linear, i.e. very simple.)
The details are complicated, both from a theoretical point of view and for the numerical implementation. All of these manifold learning algorithms are relatively similar in form: calculate some sort of matrix (in Isomap, it’s a distance matrix, in LLE, the Laplace-Beltrami operator and in HLLE, the Hessian), then do some sort of eigenvalue decomposition or similar computation on it. The matrices tend to be large (typically for N data points, hopefully reasonably sparse) which means that iterative methods are needed to solve the resulting eigenvalue problems. At the time I did this work, I was writing most of my working code in C++, so I made use of the wonderful Trilinos project, developed at Sandia. Lots of good stuff for dealing with complex matrix calculations, PDE discretisation problems, plus 101 other things. Check it out.
Application to some test data sets
So, how does it work? The traditional way to test manifold learning methods is with simple geometrical data sets, like these (the gray surfaces are the data manifolds, and the coloured points data points randomly sampled from these manifolds, perhaps with some added noise):

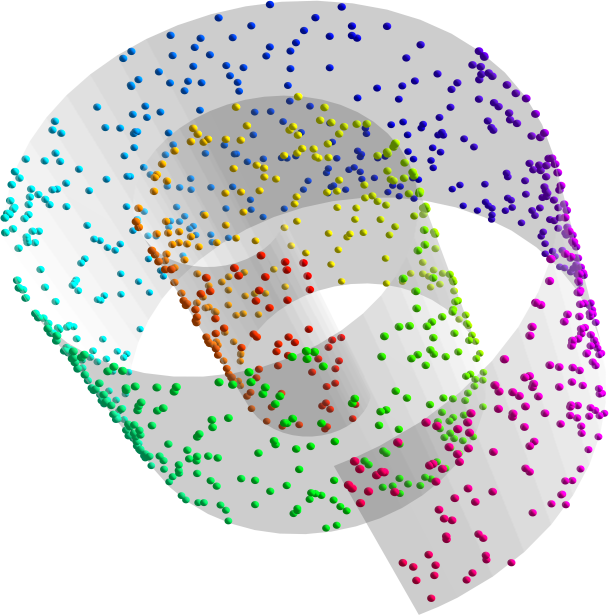
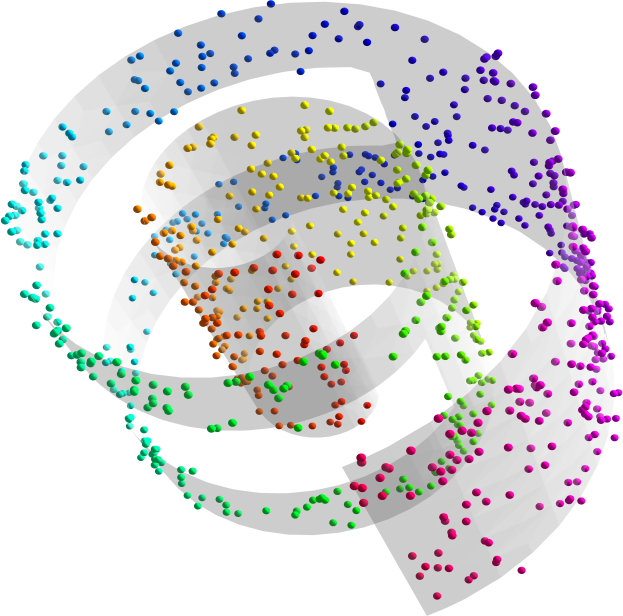
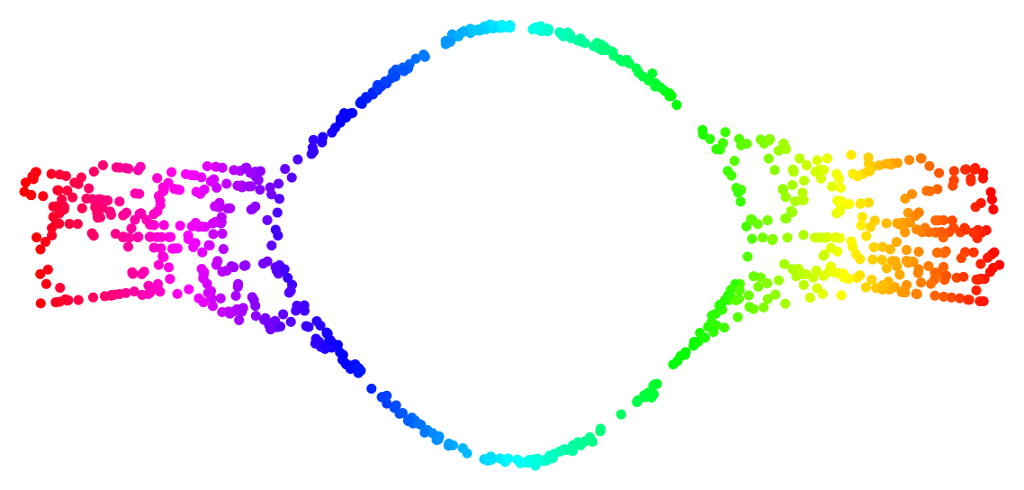
Given the three-dimensional coordinates of the coloured points, can the HLLE algorithm discover the intrinsic two-dimensional manifolds? Yes, it can:
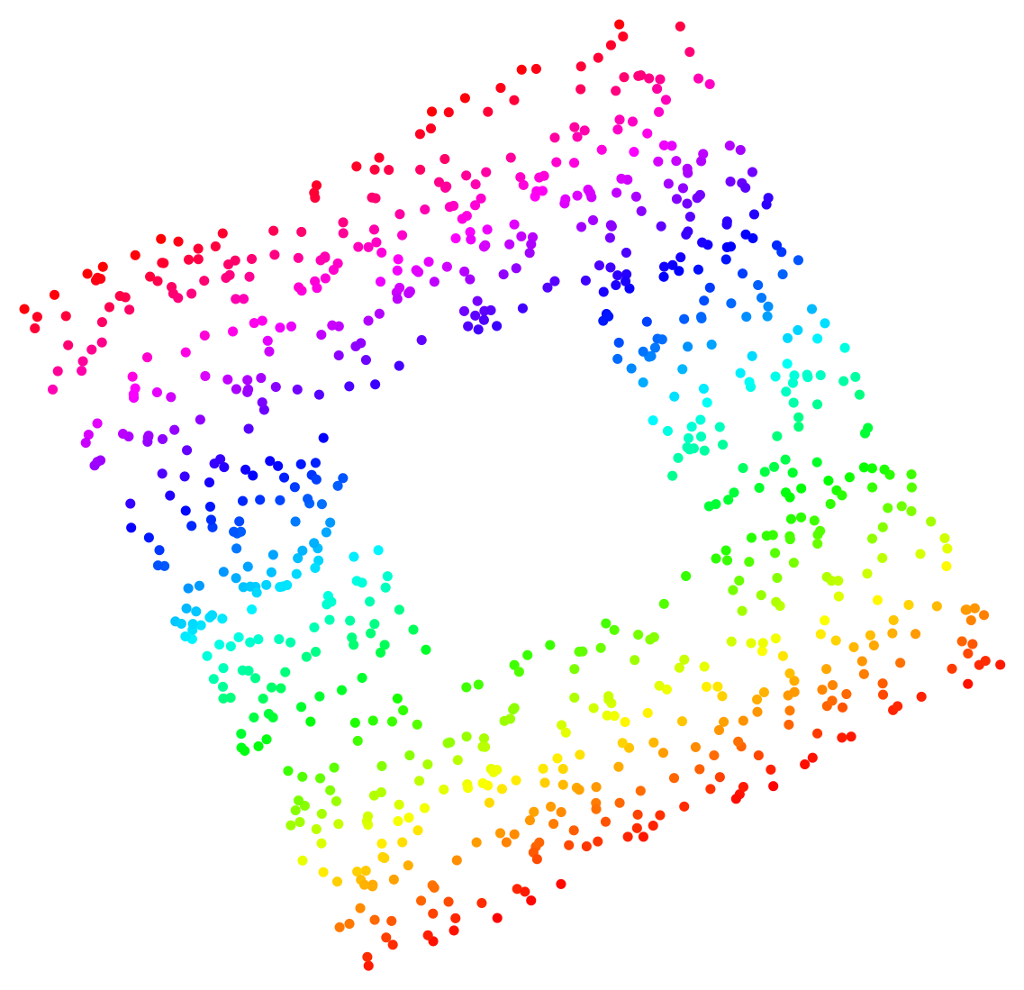
The important thing to note here, particularly in the third example (the “Swiss roll with hole”), is the lack of distortion in the “unrolling” of the manifolds to a two-dimensional representation. Compare the equivalent results from Isomap and from a neural-network nonlinear PCA method:

Parameter sensitivity
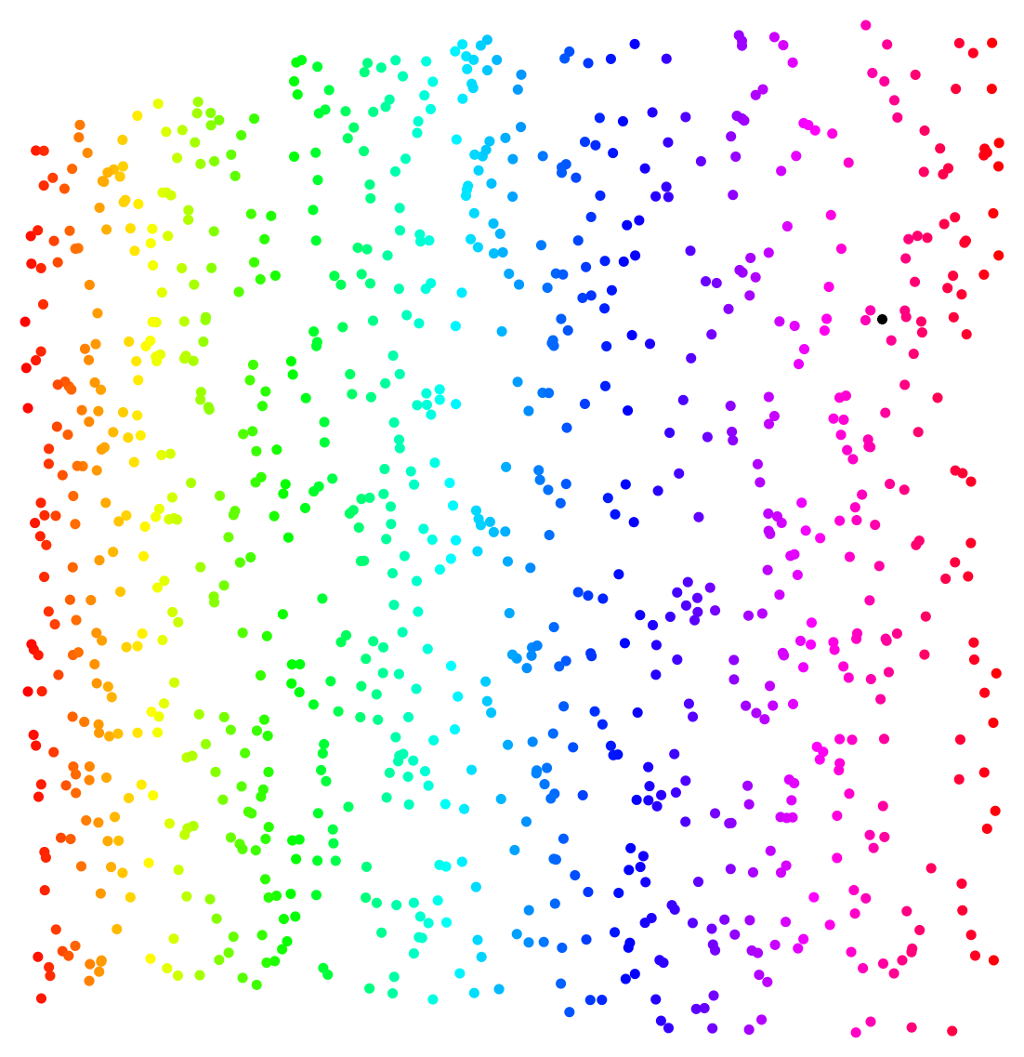
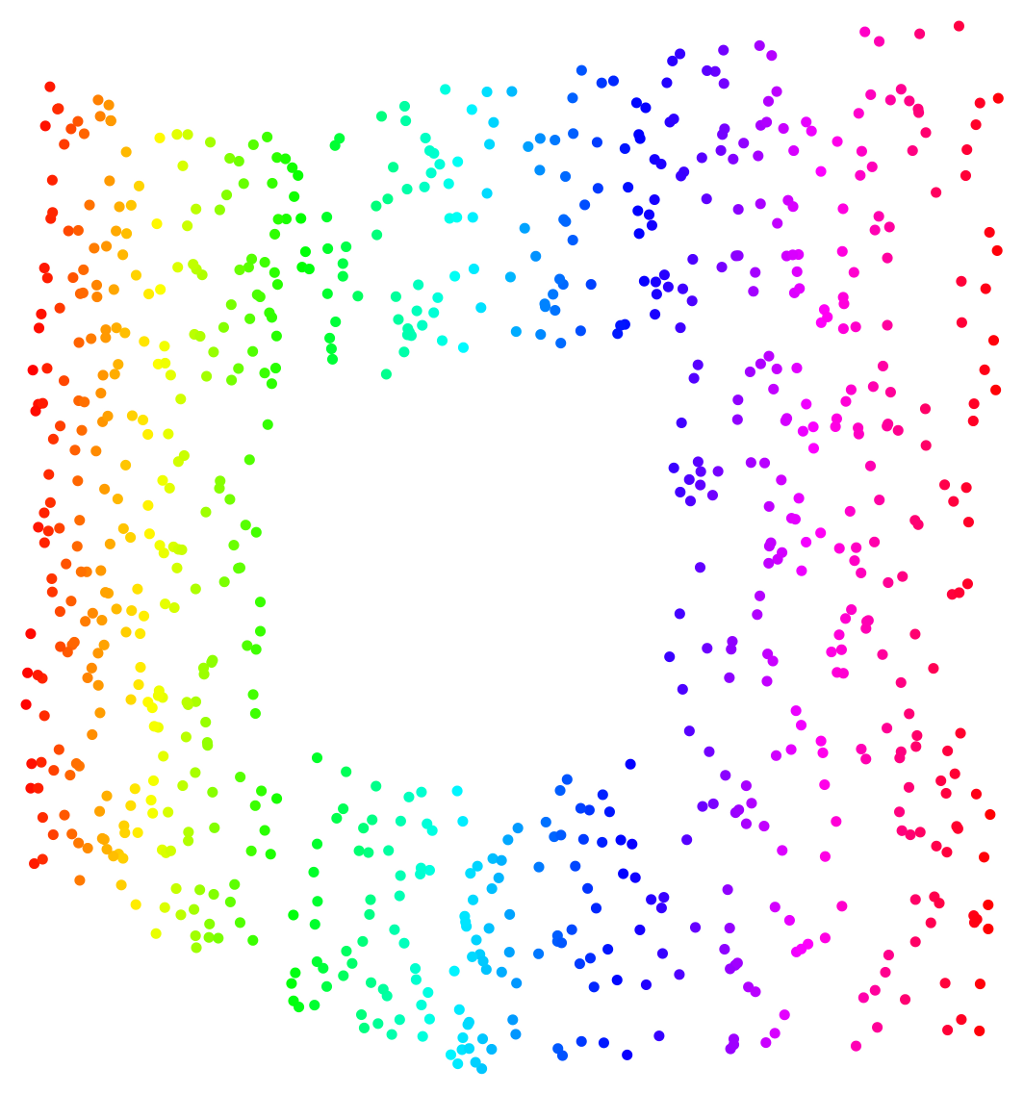
I’ve not talked about the details of the HLLE algorithm at all, but in common with a lot of similar “computational differential geometry” algorithms, at one point, a neighbourhood calculation is required (specifically, for finding locally linear subspaces by doing a local singular value decomposition). The number of points to include in these neighbourhoods is a tunable parameter of the algorithm, and it’s interesting to observe the variations in the performance of the discovery of the intrinsic data manifold as the neighbourhood size is varied. The other important factor is the total number of data points, which we can easily vary by randomly subsampling our data set. The following image shows embeddings derived for the “Swiss roll with hole” with a small amount of Gaussian noise, for a range of total data point counts and neighbourhood size (click for a really big version):
There are some striking patterns in the images here. Good embeddings are those in the central part of the image (they look like a rainbow-hued square with a hole in the middle) and exist for some values of the neighbourhood size k as long as we have enough data points (less than 1000 points and we don’t find good embeddings at all). When we don’t have enough data, embeddings for smaller k are highly distorted while those for larger k are degenerate, i.e. all data points are mapped to a single point. For intermediate values of the data point sampling density, , there is a maximum k value below which good embeddings are seen. This maximum k value increases more or less linearly from k = 14 when $N = 1000$ to k = 46 when N = 2750. As k is increased above the threshold value, embeddings show increasing distortion and eventually become degenerate.
The upper limit on the value of k to get a good embedding is imposed by the requirement that the neighbourhoods should represent “locally linear” subsets of the data manifold. When k becomes larger than the threshold seen here, the neighbourhoods start to cover regions of the data manifold that show significant curvature at the scale of the mean distance between data points. This means that the “locally linear” part of the HLLE algorithm breaks down. The maximum k value depends on the data sampling density because the neighbourhood size grows linearly with k but inversely with N — the more data points there are, the closer together they lie both in the original data space and in the lower-dimensional data manifold, and a smaller fraction of the total data manifold is encompassed by any given neighbourhood size, based on a simple count of neighbours. At the lowest data point sampling densities examined here, the Hessian LLE method does not produce good embeddings for any choice of k.
There is also a lower limit for k below which no good embeddings are seen. This limit also depends on the data sampling density. For N = 1500, the lowest neighbourhood size for which a good embedding is produced is k = 14, while for N = 4000, no good embeddings are seen for . For values of k below the lower limit, the Hessian LLE procedure identifies a one-dimensional manifold, rather than the true two-dimensional data manifold. The reason for this lower neighbourhood size limit is that, for smaller values of k, the neighbourhoods essentially sample only the noise variability in the input data, and do not capture any of the structure of the data manifold. Interestingly, the hue assignments shown in the one-dimensional manifolds appearing in these results are consistent, i.e. hues vary smoothly from one end of the embedded manifold to the other. The one-dimensional manifolds recovered from the Hessian LLE procedure appear to capture at least some aspect of the intrinsic geometry of the input data, albeit very crudely.
Application to real data
So much for carefully controlled toy data sets. The parameter sensitivity plots above show how difficult it can be to interpret the results from this kind of algorithm even for simple data (are we really seeing something intrinsic in the data or is it just an artefact of the dimensionality reduction algorithm that will go away if we change the algorithm parameters?). This problem only gets worse when confronted with realistic data. The basic problem is that, for a lot of phenomena, linear methods like PCA do surprisingly well. In particular for the climate system, there are some quite deep underlying reasons why this should be so — Gerald North showed some time ago G. R. North (1984). Empirical orthogonal functions and normal modes. J. Atmos. Sci. 41(5), 879-887. Link that PCA actually calculates the normal modes of certain stochastically driven linear dynamical systems, which makes it a natural tool for investigating the dynamics of such systems. For certain conditions, the dynamics of the atmosphere (and to some extent, the coupled ocean-atmosphere system) can be approximated by the type of system considered by North, meaning that PCA can be a good fit. In such a situation, it’s a bit optimistic to expect your smart nonlinear method to do all that much better.
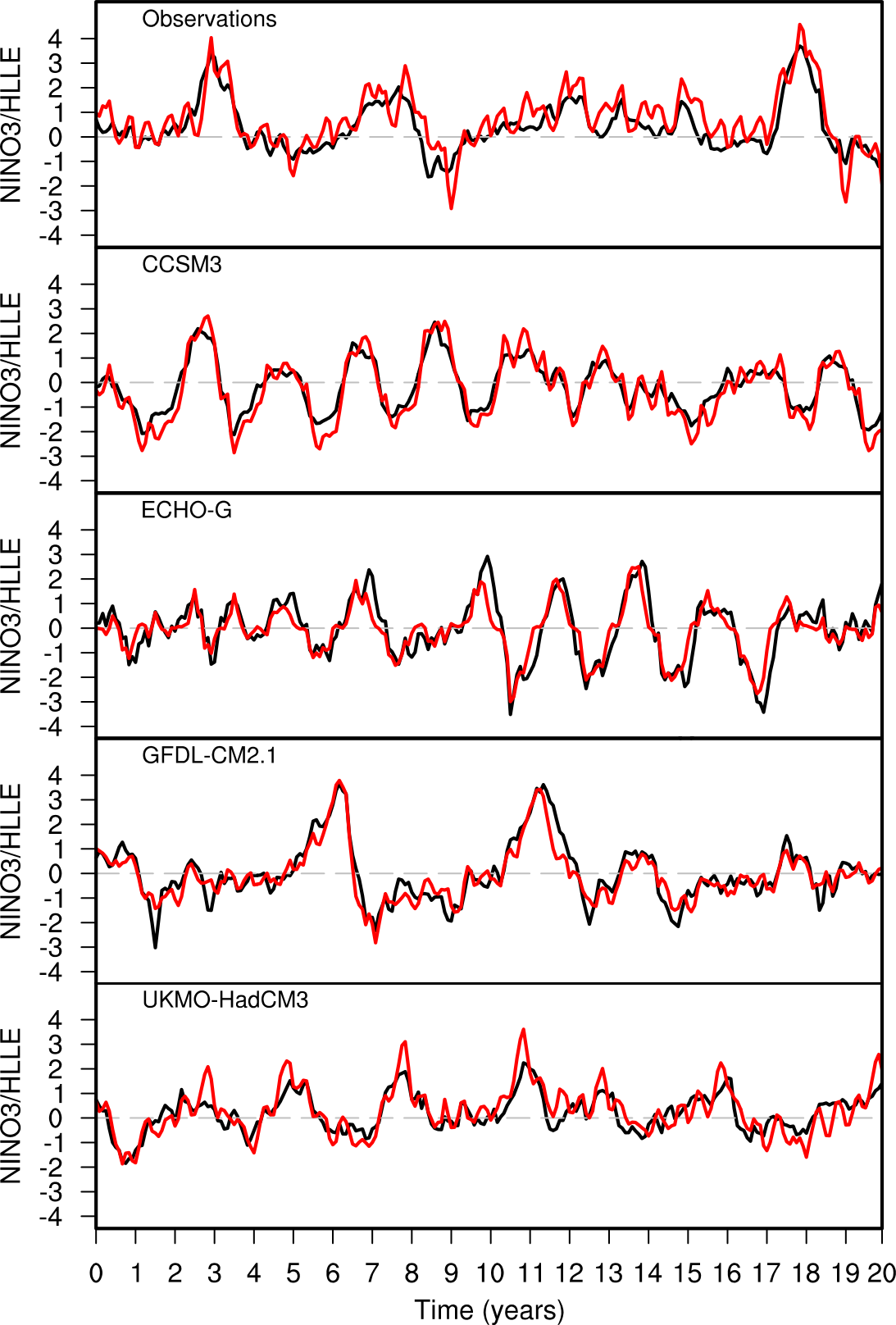
That said, these methods don’t necessarily do any worse than PCA for some climate applications. The plot to the right shows the results of applying HLLE to the analysis of interannual variability in tropical Pacific sea surface temperatures (SSTs). The two main modes of variability in this region are the annual cycle and the El Niño/Southern Oscillation (ENSO). PCA does a good job of picking out both these modes of variability, both in observational data and in the results of atmosphere-ocean general circulation models (GCMs). It turns out that HLLE can do the same (which is not something that’s immediately obvious, principally because the computation of the Hessian used in the HLLE algorithm is susceptible to problems because of numerical noise).
What the plots on the right actually show is the value of one of the components that comes out of the HLLE analysis, rotated into a coordinate frame that “unmixes” variations due solely to the annual cycle. The hope is that this procedure will pick out variability due to ENSO. In the plots, you can see an index of ENSO variability (in black, derived from mean SSTs over a specified region in the equatorial Pacific) and the rotated HLLE component time series in red, both for observational data and for four GCMs from the CMIP3 ensemble. What’s quite interesting here is that the HLLE algorithm manages to pick out the ENSO (or ENSO-like) variability in both the observations and most of the model data sets, without any prompting. This is not a particularly shocking result, since PCA does the same, but it’s quite encouraging to see that these more complex methods are at least no worse that linear methods when such methods are appropriate.
There are situations where there definitely is a lower-dimensional nonlinear manifold to be discovered, and in these cases, algorithms like Isomap or HLLE can do a lot better than a linear method like PCA. You need to experiment to find out whether that really is the case though: it’s very easy to pick a method because it’s “fashionable” and demonstrate the existence of a “nonlinear” manifold that’s just as easily discovered using a linear method. The literature on nonlinear dimensionality reduction is littered with studies of this sort.
The take-home lesson? Data analysis is hard, and clever methods add a extra burden of understanding on top that’s not always justified.