The simplex algorithm: warm-up
Pathetically slow in starting work on my little constraints project as I am, here’s the first of what should be a long series of posts…
One of the constraint solvers I’m looking at starting from, Cassowary, uses what is essentially an extended version of one of the most venerable of optimisation algorithms, Dantzig’s simplex algorithm. I’m going to start off thinking a little bit about the general setup of the kind of linear programming problems that the simplex algorithm is designed to solve, just to get a geometrical feeling for how these algorithms work and to understand the issues that might arise from relaxing some of the assumptions used in them.
Setup
The basic idea of linear programming problems is to find a vector that maximises a linear objective function
subject to M linear constraints of the form , or . There is lots of specialised terminology surrounding the field of linear programming, but this is the basic idea.
What’s the connection between this sort of problem and the problem of laying out diagrams? In a diagram, the variables that we are interested in determining, i.e. the components of the vector , are the coordinates of certain points in our diagram: perhaps the end points of line segments, the centres of circles, whatever points we’ve included in our constraints. The dimension of the solution space, N, is then just the total number of coordinates we need to find. If we can express our geometrical constraints as linear equations or inequalities between these coordinates, and if we can express a “good” layout for underconstrained situations as a linear function of our coordinate values, then we have a linear programming problem to solve.
Most of the time, we hope that the constraints we impose are sufficient to precisely locate all the elements of the diagram, in which case there is only one possible solution to the constraint equations and our linear programming problem degenerates to the solution of a system of linear equations to determine the unique point satisfying the constraints. On the other hand, if we are building a system of constraints interactively, we will often find ourselves with an underconstrained system — the user has placed a number of shapes, has applied some constraints between them, but those constraints are not sufficient to fix the positions of all the elements of the diagram. We might then choose some optimisation criterion to decide what is a good layout for the underconstrained drawing In fact, things are trickier than this. Following the principle of least surprise, adding constraints to a drawing should only cause elements of the drawing to move around if they are in positions inconsistent with the constraints that have been applied so far. The Cassowary solver algorithm is constructed to allow this sort of update. I’ll talk about that another time, since it’s a bit more complicated than the basic simplex algorithm. .
What sort of constraints can we treat? Suppose we have three points , and . We can make two points be coincident, for example with the constraint . We can make the point lie on the line segment connecting points and using the constraints
where we introduce an auxiliary variable t. We can express the condition that the line segment between points and be horizontal by saying , that it be vertical by saying , or in general that it lie at any given angle by saying
where again we introduce an auxiliary variable t.
However, we can’t demand that the distance between points and is at most a particular value, d say, since to express this constraint, we would need to say something like
which is not a linear constraint. That seems like a bit of a shame, since distance-based constraints are very natural from a geometrical point of view. I’ll talk below about what it might mean to lift the restriction to linear constraints.
Finding solutions
First of all, let’s think about how the constraints that we impose restrict the space of solutions to our optimisation problem. If , then the linear equality defines an N-1-dimensional hyperplane in . For concreteness, for the moment let’s set N=3. In 3-dimensional Euclidean space, the equation , where is an unknown vector, is a given unit vector, and is a real number, defines a plane with normal vector and perpendicular distance from the origin , i.e. solutions to this equation lie in the given plane. So the solutions to our optimisation problem have to lie in this plane, not just in . If we have a second equality constraint, defined by the equation , there are three possibilities: either and so both equalities refer to the same plane; or and or and , a situation where we have two distinct parallel planes and there are thus no consistent solutions for ; or and are not collinear, the planes are distinct and meet in a line, to which our solutions are constrained. In higher dimensional spaces, adding further equality constraints works in the same way: either we have a degenerate case, so there are no admissible solutions, or the additional constraints restrict the admissible solutions to smaller and smaller linear subspaces of the original solution space.
In the end, after considering all of the linear equality constraints, we thus end up with a situation where we need to seek solutions in some linear subspace of , subject to our inequality constraints. Further, there always exists a linear transformation that can simplify our view of this linear subspace so that we end up considering an optimisation problem in a lower-dimensional Euclidean space, say, with , with only inequality constraints of the form or .
Next, let’s think about the role of the inequality constraints in restricting the solution space. Each inequality constraint of the form or divides the space into two half-spaces, one in the permissible solution region and one not. The final permissible region is the intersection of the permissible half-spaces from each of these constraints. A little thought shows that this is a convex polytope A polygon lives in ; a polyhedron lives in ; a polytope lives in general . in .
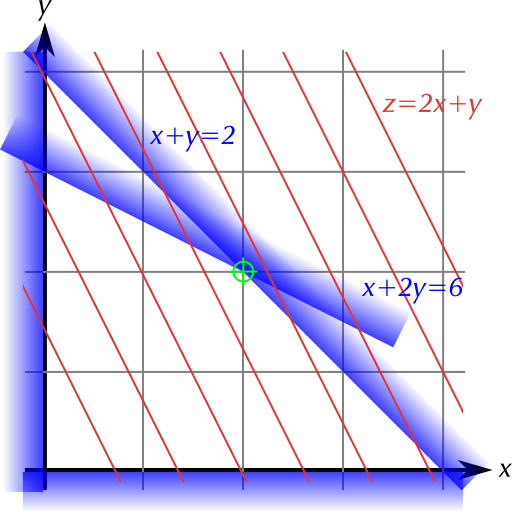
Here’s an example in . Let’s call our coordinates x and y. Suppose we have the constraints , (these two are normally included by default in the “traditional” statement of the setup for the simplex algorithm), and .
The figure above shows the constraints as blue boundaries, with the interior of the polygon bounded by the constraint lines being the set of permissible solutions. I’ve also show the contours of a particular gradient function (the red lines) and the resulting best solution (point marked in green). It’s pretty clear that adding more linear inequality constraints can’t make the permissible region anything other than a convex polygon.
It’s also pretty clear from this image that the optimal point, i.e. the maximum of the objective function z, is going to be found on the boundary of the polygon defined by the constraints. To see this, suppose that we select some point in the interior of the polygon as our putative “best” point. Then we can always go downhill along the contours of the objective function until we reach the boundary of the permissible polygon, thus finding a better solution than our originally proposed one.
In fact, the optimal solution, except in degenerate cases, is found at one of the vertices of this polygon. This is the key point that makes this type of optimisation problem more tractable than it might initially seem: even with large numbers of dimensions, we basically only need to solve a combinatorics problem over the vertices of our permissible polygon. In particular, we don’t need to think about what happens to our objective function in the interior of the polygon. This is a big deal, and we’ll see how lifting the linearity requirement on either the constraints or the objective function renders the problem much more difficult.
In essence, the simplex algorithm is a smart way of doing this combinatorial search along the edges of our permissible polygon, in a way that works for larger problems and with some special cases to deal with degenerate problems and to detect insoluble problems.
Lifting assumptions
What happens if we lift the requirement that constraints be linear? A general nonlinear equation in defines a manifold Well, really, a variety, but varieties make me itchy, so I’m going to pretend that the solution set of all equations here is a nice smooth manifold. embedded in , so nonlinear equality constraints, instead of reducing our solution space to a nonlinear subspace of , will reduce it to a manifold on which possible solutions live. Theoretically, this isn’t too much of a problem, but from a practical point of view, it might be tricky to deal with. In principle, we can find some sort of coordinate transform to make nice charts on our manifold U we can use to think about our inequality constraints, but even in simple cases, care is required to make sure that our charts make a good atlas for the manifold. Suppose N=3, we call our coordinates x, y and z and we have a constraint that , i.e. solutions lie on the surface of a sphere of radius one centred on the origin. Geometrically, this is no problem, but if we seek a single coordinate transformation to represent the two-dimensional surface of the sphere, say, we get into trouble: we need at least two distinct charts to form an atlas for the 2-sphere. It may thus be necessary to continue to work in the original (x,y,z) coordinate system, even though these are not independent degrees of freedom in the problem.
Nonlinear inequality constraints pose another sort of problem. If we have an inequality like , i.e. (x,y) lies inside a circle of radius 2 centred on the origin, although, given a linear objective function, the optimal point still lies on the boundary of the region defined by the inequality, finding that point is rather more difficult and is no longer a simple combinatorial optimisation over the vertices of a polygon, as in the simplex algorithm.
There is another problem with nonlinear inequalities. Recall that for the linear constraint case, the permissible region was always a convex polytope. In general, nonlinear constraints do not guarantee convex regions (think of the constraints , , , for instance) and this can lead to kinds of degenerate problem that do not exist in the linear case (for this set of constraints, optimising the objective z = x + y leads to two solutions, one on each of the “corners” of the concave arc defined by the hyperbola equation xy = 1). It seems like it might be possible to restrain ourselves to inequalities defining convex regions, which would mean that the permissible region formed from the intersection of these regions would also be convex If a region R is convex, then for any two points and in R, then all points with are also in R. If we denote a second convex region by S, then for any two points x and y in , we have that , and for , and also that , and for . Thus for and so is also convex. . Something to think about a bit more, particularly since there are optimisation methods designed for these convex situations.
Lifting the assumption that our objective function is linear means that we can no longer be sure that the optimal value lies on the boundary of our permissible region. An arbitrary nonlinear function can have all sorts of bumps and maxima within the permissible region. There are classes of nonlinear functions (in particular harmonic functions) where we can make definitive statements about extremal values within the permissible region compared to on the boundary, but these don’t seem like practical classes to use to restrict the choice of objective. All other things being equal, a linear objective is probably the best approach for now.
Conclusions and what next?
Linear constraints and linear objective function are nice and easy to understand geometrically.
General nonlinear constraints are potentially nasty.
Convex nonlinear constraints might be easier to handle (there’s a whole field called convex optimisation about dealing with this situation) and it seems intuitively likely that most of the nonlinear constraints we’re interested in might be convex — distance constraints essentially define balls in the coordinate space, for example.
Nonlinear objective functions break the whole “optimal solution on the boundary” idea. Best avoided if possible…
Next, I’m going to set things up to play with an implementation of the simplex algorithm in Haskell, along the way experimenting with an interface for specifying constraint systems.