Non-diffusive atmospheric flow #10: significance of flow patterns
The spherical PDF we constructed by kernel density estimation in the article before last appeared to have “bumps”, i.e. it’s not uniform in and . We’d like to interpret these bumps as preferred regimes of atmospheric flow, but before we do that, we need to decide whether these bumps are significant. There is a huge amount of confusion that surrounds this idea of significance, mostly caused by blind use of “standard recipes” in common data analysis cases. Here, we have some data analysis that’s anything but standard, and that will rather paradoxically make it much easier to understand what we really mean by significance.
So what do we mean by “significance”? A phenomena is significant if it is unlikely to have occurred by chance. Right away, this definition raises two questions. First, chance implies some sort of probability, a continuous quantity, which leads to the idea of different levels of significance. Second, if we are going to be thinking about probabilities, we are going to need to talk about a distribution for those probabilities. The basic idea is thus to compare our data to a distribution that we explicitly decide based on a null hypothesis. A bump in our PDF will be called significant if it is unlikely to have occurred in data generated under the assumptions in our null hypothesis.
So, what’s a good null hypothesis in this case? We’re trying to determine whether these bumps are a significant deviation from “nothing happening”. In this case, “nothing happening” would mean that the data points we use to generate the PDF are distributed uniformly over the unit sphere parametrised by and , i.e. that no point in space is any more or less likely to occur than any other. We’ll talk more about how we make use of this idea (and how we sample from our “uniform on the sphere” null hypothesis distribution) below.
We thus want some way of comparing the PDF generated by doing KDE on our data points to PDFs generated by doing KDE on “fake” data points sampled from our null hypothesis distribution. We’re going to follow a sampling-based approach: we will generate “fake” data sets, do exactly the same analysis we did on our real data points to produce “fake” PDFs, then compare these “fake” PDFs to our real one (in a way that will be demonstrated below).
There are a couple of important things to note here, which I usually think of under the heading of “minimisation of cleverness”. First, we do exactly the same analysis on our “fake” data as we do on our “real” data. That means that we can treat arbitrarily complex chains of data analysis without drama: here, we’re doing KDE, which is quite complicated from a statistical perspective, but we don’t really need to think about that, because the fact that we treat the fake and real data sets identically means that we’re comparing like with like and the complexity just “divides out”. Second, because we’re simulating, in the sense that we generate fake data based on a null hypothesis on the data and run it through whatever data analysis steps we’re doing, we make any assumptions that go into our null hypothesis perfectly explicit. If we assume Gaussian data, we can see that, because we’ll be sampling from a Gaussian to generate our fake data. If, as in this case, our null hypothesis distribution is something else, we’ll see that perfectly clearly because we sample directly from that distribution to generate our fake data.
This is a huge contrast to the usual case for “normal” statistics, where one chooses some standard test (t-test, Mann-Whitney test, Kolmogorov-Smirnov test, and so on) and turns a crank to produce a test statistic. In this case, the assumptions inherent in the form of the test are hidden — a good statistician will know what those assumptions are and will understand the consequences of them, but a bad statistician (I am a bad statistician) won’t and will almost certainly end up applying tests outside of the regime where they are appropriate. You see this all the time in published literature: people use tests that are based on the assumption of Gaussianity on data that clearly isn’t Gaussian, people use tests that assume particular variance structures that clearly aren’t correct, and so on. Of course, there’s a very good reason for this. The kind of sampling-based strategy we’re going to use here needs a lot of computing power. Before compute power was cheap, standard tests were all that you could do. Old habits die hard, and it’s also easier to teach a small set of standard tests than to educate students in how to design their own sampling-based tests. But we have oodles of compute power, we have a very non-standard situation, and so a sampling-based approach allows us to sidestep all the hard thinking we would have to do to be good statisticians in this sense, which is what I meant by “minimisation of cleverness”.
So, we’re going to do sampling-based significance testing here. It is shockingly easy to do and, if you’ve been exposed to the confusion of “traditional” significance testing, shockingly easy to understand.
Simulating from the null hypothesis
In order to test the significance of the bumps we see in our spherical PDF, we need some way of sampling points from our null hypothesis distribution, i.e. from a probability distribution that is uniform on the unit sphere. The simplest way to do this is to sample points from a spherically symmetric three-dimensional probability distribution then project those points onto the unit sphere. The most suitable three-dimensional distribution, at least from the point of view of convenience, is a three dimensional Gaussian distribution with zero mean and unit covariance matrix. This is particularly convenient because if we sample points from this distribution, each of the coordinates x, y and z are individually distributed as a standard Gaussian, i.e. , , . To generate N random points uniformly distributed on the unit sphere, we can thus just generate 3N standard random deviates, partition them into 3-vectors and normalise each vector. Haskell code to do this sampling using the mwc-random package is shown below — here, nData is the number of points we want to sample, and the randPt function generates a single normalised (x, y, z) as a Haskell 3-tuple (as usual, the code is in a Gist; this is from the make-unif-pdf-sample.hs program):
-- Random data point generation.
gen <- create
let randPt gen = do
unnorm <- SV.replicateM 3 (standard gen)
let mag = sqrt $ unnorm `dot` unnorm
norm = scale (1.0 / mag) unnorm
return (norm ! 0, norm ! 1, norm ! 2)
-- Create random data points, flatten to vector and allocate on
-- device.
dataPts <- replicateM nData (randPt gen)If we sample the same number of points from this distribution that we have in our real data and then use the same KDE approach the we used for the real data to generate an empirical PDF on the unit sphere, what do we get? Here’s what one distribution generated by this procedure looks like, using the same colour scale as the “real data” distribution in the earlier article to aid in comparison (darker colours show regions of greater probability density):
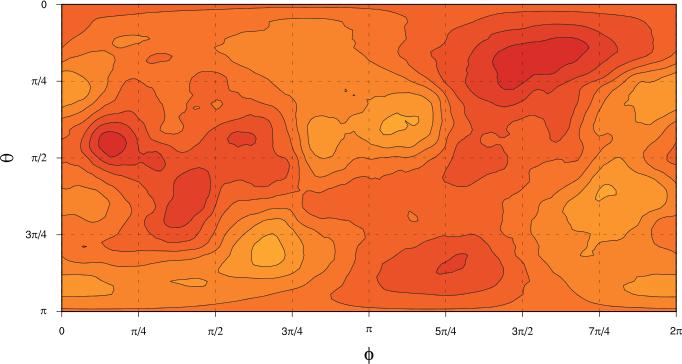
We can see that our sample from the null hypothesis distribution also has “bumps”, although they seem to be less prominent than the bumps in PDF for our real data. Why do we see bumps here? Our null hypothesis distribution is uniform, so why is the simulated empirical PDF bumpy? The answer, of course, is sampling variation. If we sample 9966 points on the unit sphere, we are going to get some clustering of points (leading to bumps in the KDE-derived distribution) just by chance. Those chance concentrations of points are what lead to the bumps in the plot above.
What we ultimately want to do then is to answer the question: how likely is it that the bumps in the distribution of our real data could have arisen by chance, assuming that our real data arose from a process matching our null hypothesis?
Testing for significance
The way we’re going to answer the question posed in the last section is purely empirically. We’re going to generate empirical distributions (histograms) of the possible values of the null hypothesis distribution to get a picture of the sampling variability that is possible, then we’re going to look at the values of our “real data” distribution and calculate the proportion of the null hypothesis distribution values less than the real data distribution values. This will give us the probability that our real data distribution could have arisen by chance if the data really came from the null hypothesis distribution.
In words, it sounds complicated. In reality and in code, it’s not. First, we generate a large number of realisations of the null hypothesis distribution, by sampling points on the unit sphere and using KDE to produce PDFs from those point distributions in exactly the same way that we did for our real data, as shown here (code from the make-hist.hs program):
-- Generate PDF realisations.
pdfs <- forM [1..nrealisations] $ \r -> do
putStrLn $ "REALISATION: " ++ show r
-- Create random data points.
dataPts <- SV.concat <$> replicateM nData (randPt gen)
SV.unsafeWith dataPts $ \p -> CUDA.pokeArray (3 * nData) p dDataPts
-- Calculate kernel values for each grid point/data point
-- combination and accumulate into grid.
CUDA.launchKernel fun gridSize blockSize 0 Nothing
[CUDA.IArg (fromIntegral nData), CUDA.VArg dDataPts, CUDA.VArg dPdf]
CUDA.sync
res <- SVM.new (ntheta * nphi)
SVM.unsafeWith res $ \p -> CUDA.peekArray (ntheta * nphi) dPdf p
unnormv <- SV.unsafeFreeze res
let unnorm = reshape nphi unnormv
-- Normalise.
let int = dtheta * dphi * sum (zipWith doone sinths (toRows unnorm))
return $ cmap (realToFrac . (/ int)) unnorm :: IO (Matrix Double)(This is really the key aspect of this sampling-based approach: we perform exactly the same data analysis on the test data sampled from the null hypothesis distribution that we perform on our real data.) We generate 10,000 realisations of the null hypothesis distribution (stored in the pdfs value), in this case using CUDA to do the actual KDE calculation, so that it doesn’t take too long.
Then, for each spatial point on our unit sphere, i.e. each point in the grid that we’re using, we collect all the values of our null hypothesis distribution — this is the samples value in this code:
-- Convert to per-point samples and generate per-point histograms.
let samples = [SV.generate nrealisations (\s -> (pdfs !! s) ! i ! j) :: V |
i <- [0..ntheta-1], j <- [0..nphi-1]]
(rngmin, rngmax) = range nbins $ SV.concat samples
hists = map (histogram_ nbins rngmin rngmax) samples :: [V]
step i = rngmin + d * fromIntegral i
d = (rngmax - rngmin) / fromIntegral nbins
bins = SV.generate nbins stepFor each point on our grid on the unit sphere, we then calculate a histogram of the samples from the 10,000 empirical PDF realisations, using the histogram_ function from the statistics package. We use the same bins for all the histograms to make life easier in the next step.
There’s one thing that’s worth commenting on here. You might think that we’re doing excess work here. Our null hypothesis distribution is spherically symmetric, so shouldn’t the histograms be the same for all points on the unit sphere? Well, should they? Or might the exact distribution of samples depend on , since the grid cells will be smaller at the poles of our unit sphere than at the equator? Well, to be honest, I don’t know. And I don’t really care. By taking the approach I’m showing you here, I don’t need to worry about that question, because I’m generating independent histograms for each grid cell on the unit sphere, so my analysis is immune to any effects related to grid cell size. Furthermore, this approach also enables me to change my null hypothesis if I want to, without changing any of the other data analysis code. What if I decide that this spherically symmetric null hypothesis is too weak? What if I want to test my real data against the hypothesis that there is a spherically symmetric background distribution of points on my unit sphere, plus a couple of bumps (of specified amplitude and extent) representing what I think are the most prominent patterns of atmospheric flow? That’s quite a complicated null hypothesis, but as long as I can define it clearly and sample from it, I can use exactly the same data analysis process that I’m showing you here to evaluate the significance of my real data compared to that null hypothesis. (And sampling from a complicated distribution is usually easier than doing anything else with it. In this case, I might say what proportion of the time I expect to be in each of my bump or background regimes, for the background I can sample uniformly on the sphere and for the bumps I can sample from a Kent distribution This is a sort of “bump” distribution on the unit sphere (see on Wikipedia). .)
Once we have the histograms for each grid point on the unit sphere, we can calculate the significance of the values of the real data distribution (this is from the make-significance.hs program — I split these things up to make checking what was going on during development easier):
-- Split histogram values for later processing.
let nhistvals = SV.length histvals
oneslice i = SV.slice i nbin histvals
histvecs = map oneslice [0, nbin.. nhistvals - nbin]
hists = A.listArray ((0, 0), (ntheta-1, nphi-1)) histvecs
nrealisations = SV.sum $ hists A.! (0, 0)
-- Calculate significance values.
let doone :: CDouble -> CDouble -> CDouble
doone dith diph =
let ith = truncate dith ; iph = truncate diph
pdfval = pdf ! ith ! iph
hist = hists A.! (ith, iph)
pdfbin0 = truncate $ (pdfval - minbin) / binwidth
pdfbin = pdfbin0 `max` 0 `min` nbin - 1
in (SV.sum $ SV.take pdfbin hist) / nrealisations
sig = build (ntheta, nphi) doone :: Matrix CDoubleWe read the histograms into the histvals value from an intermediate NetCDF file and build an array of histograms indexed by grid cell indexes in the and directions. Then, for each grid cell, we determine which histogram bin the relevant value from the real data distribution falls into and sum the histogram values from the corresponding histogram from all the bins smaller than the real data value bin. Dividing this sum by the total number of null hypothesis distribution realisations used to construct the histograms gives us the fraction of null hypothesis distribution values for this grid cell that are smaller than the actual value from the real data distribution.
For instance, if the real data distribution value is greater than 95% of the values generated by the null hypothesis distribution simulation, then we say that we have a significance level of 95% at that point on the unit sphere. We can plot these significance levels in the same way that we’ve been plotting the spherical PDFs. Here’s what those significance levels look like, choosing contour levels for the plot to highlight the most significant regions, i.e. the regions least likely to have occurred by chance if the null hypothesis is true:
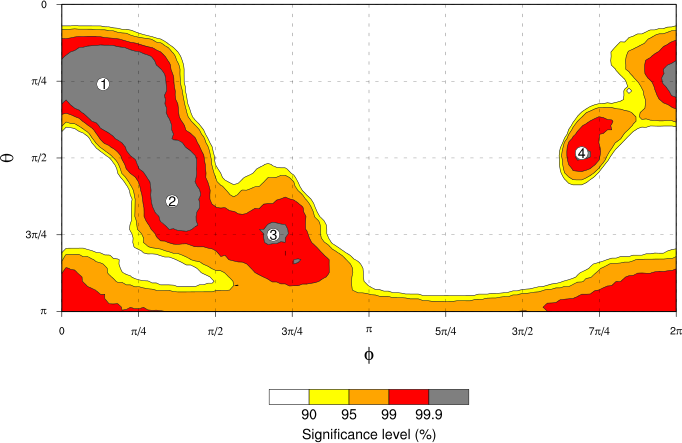
In particular, we see that each of the three bumps picked out with labels in the “real data” PDF plot in the earlier article are among the most significant regions of the PDF according to this analysis, being larger than 99.9% of values generated from the null hypothesis uniform distribution.
It’s sort of traditional to try to use some other language to talk about these kinds of results, giving specific terminological meanings to the words “significance levels” and “p-values”, but I prefer to keep away from that because, as was the case for the terminology surrounding PCA, the “conventional” choices of words are often confusing, either because no-one can agree on what the conventions are (as for PCA) or the whole basis for setting up the conventions is confusing. In the case of hypothesis testing, there are still papers being published in statistical journals arguing about what significance and p-values and hypothesis testing really mean, nearly 100 years after these ideas were first outlined by Ronald Fisher and others. I’ve never been sure enough about what all this means to be comfortable using the standard terminology, but the sampling-based approach we’ve used here makes it much harder to get confused — we can say “our results are larger than 99.9% of results that could be encountered as a result of sampling variability under the assumptions of our null hypothesis”, which seems quite unambiguous (if a little wordy!).
In the next article we’ll take a quick look at what these “bumps” in our “real data” PDF represent in terms of atmospheric flow.